Despite the remarkable performance of deep neural networks on various computer vision tasks, they are known to be susceptible to adversarialperturbations, which makes it challenging to deploy them in real-world safety-critical applica-tions. In this post, we discuss our latest paper, that aims to minimize the feature-level distortion during training. Our results show that, suppressing the feature-level distortion improves the robustness of the network while using only a fraction of the parameters used by the full network. The code can be be found online.
Robustness of deep representations
We conjecture that the leading cause of adversarial vulnerability is the distortionin the latent feature space. If a perturbation at the input level is suppressed successfully at any layers of the DNN, then it would not cause miss-prediction. However, not all latent features will contribute equally to the distortion; some features may have more substantial distortion, by amplifying the perturbations at the input level, while others will remain relatively static. Under this motivation, we first define the concept of vulnerability in the deep latent representation space.
Specifically, the vulnerability of a latent feature of a network is the expectation of the Manhattan distance between the latent-feature value for a clean example \((z)\) and its adversarial example \((\tilde{z})\).
\[{\rm{v}}(z_{lk},\tilde{z}_{lk}) = \mathbb{E}_{(x,y)\sim\mathcal{D}}| z_{lk} - \tilde{z}_{lk} | \]
We can measure the vulnerability of an entire network by computing the sum of the vulnerability of all the latent features vectors of the network before the logit layer:
\[{\rm{V}}(f_{\theta}(X), f_{\theta}(\tilde{X})) = \frac{1}{L-2}\sum_{l=1}^{l=L-2} \sum_{k=1}^{k=N_l} {\rm{v}}(z_{lk},\tilde{z}_{lk}), \]
Adversarial Neural Pruning with Latent Vulnerability Suppression
In order to suppress the vulnerability in the feature space, we propose a novel loss, which we refer to as Vulnerability Suppression (VS) loss, that directly suppresses the vulnerability in the feature space by minimizing the feature-level vulnerability. While VS could be used as a regularization to minimize the feature-level vunlerability, an even more effective way to suppress vulnerability will be to completely eliminate the latent features with high vulnerability by pruning them, as illustrated below:
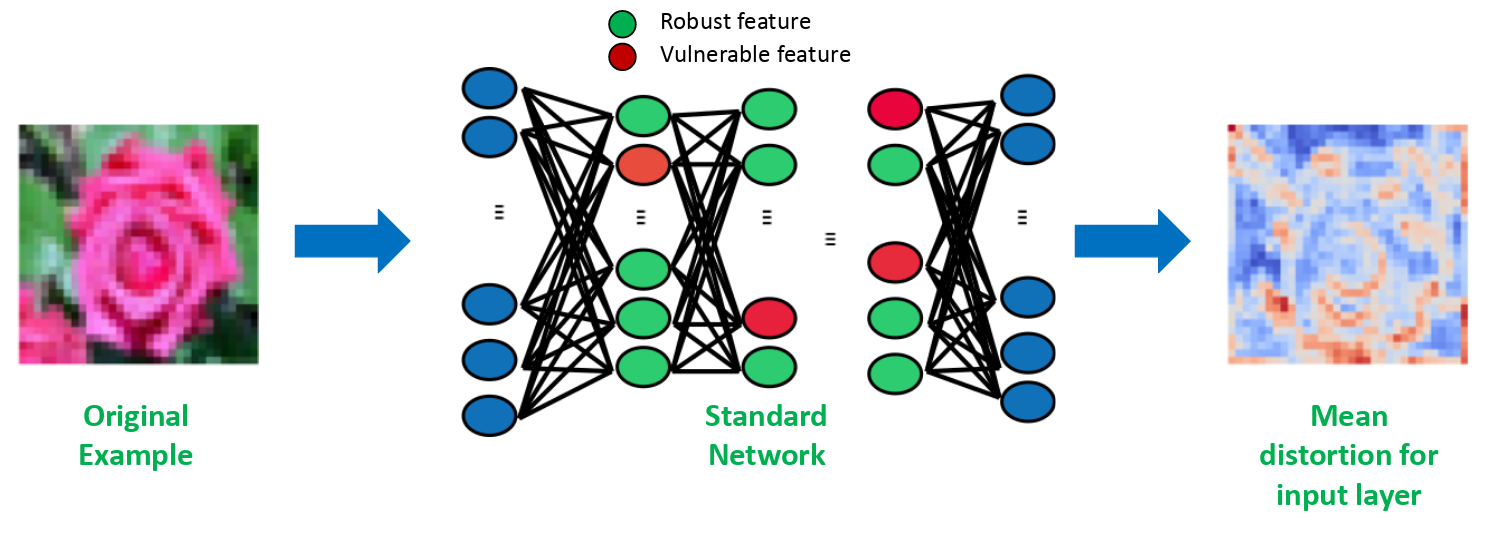
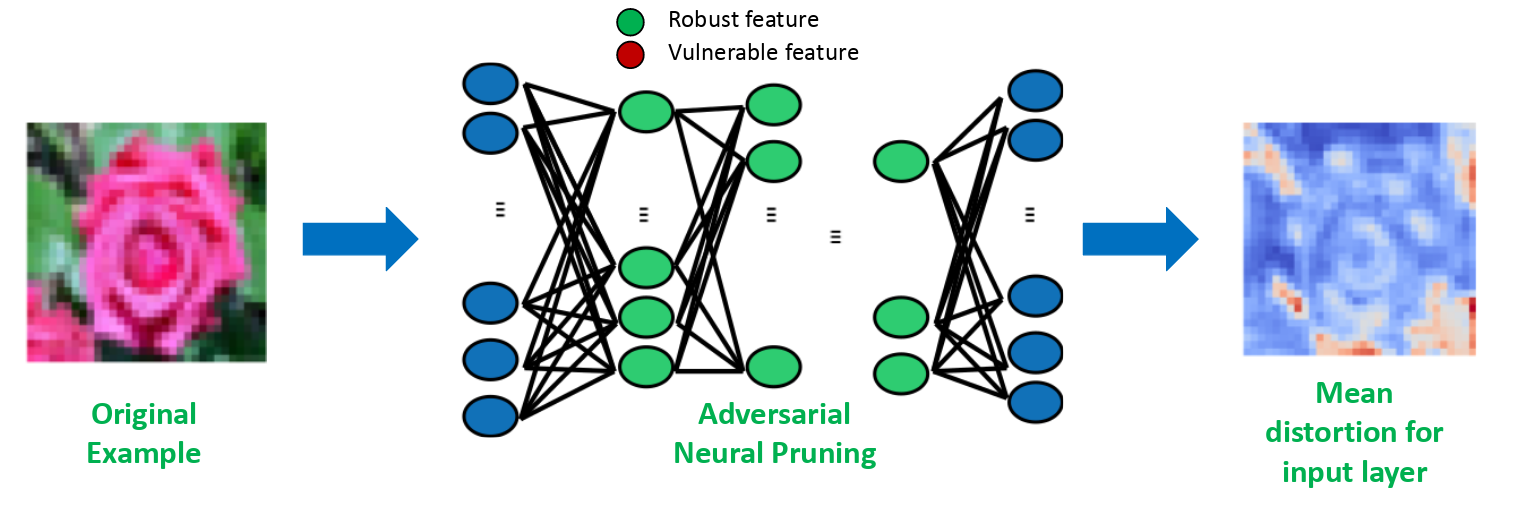
The Figure demonstrates the mean distortion for the input layer of a network. As we can see, pruning the vulnerable latent-features suppresses the vulnerability of the netowrk. Guo et al. used weight pruning and activation pruning to show that sparsifying networks leads to more robust networks. The actual reason behind the robustness is obvious by our definitions: sparsity suppresses vulnerability to 0 and thus reduces the vulnerability of the network. Yet, the network still does not take into account the robustness of a feature.
In order to suppress vulnerability, we prue the latent features with high vulnerability. We refer to this defense mechanism as Adversarial Neural Pruning (ANP). Specifically, ANP learns pruning (dropout) masks for the features in a Bayesian framework to mitigate the feature-level vulnerability. To this end, we formulate, Adversarial Neural Pruning with Vulnerability Suppression (ANP-VS), that learns pruning masks for the features in a Bayesian framework to minimize both the adversarial loss and the feature-level vulnerability as shown below:
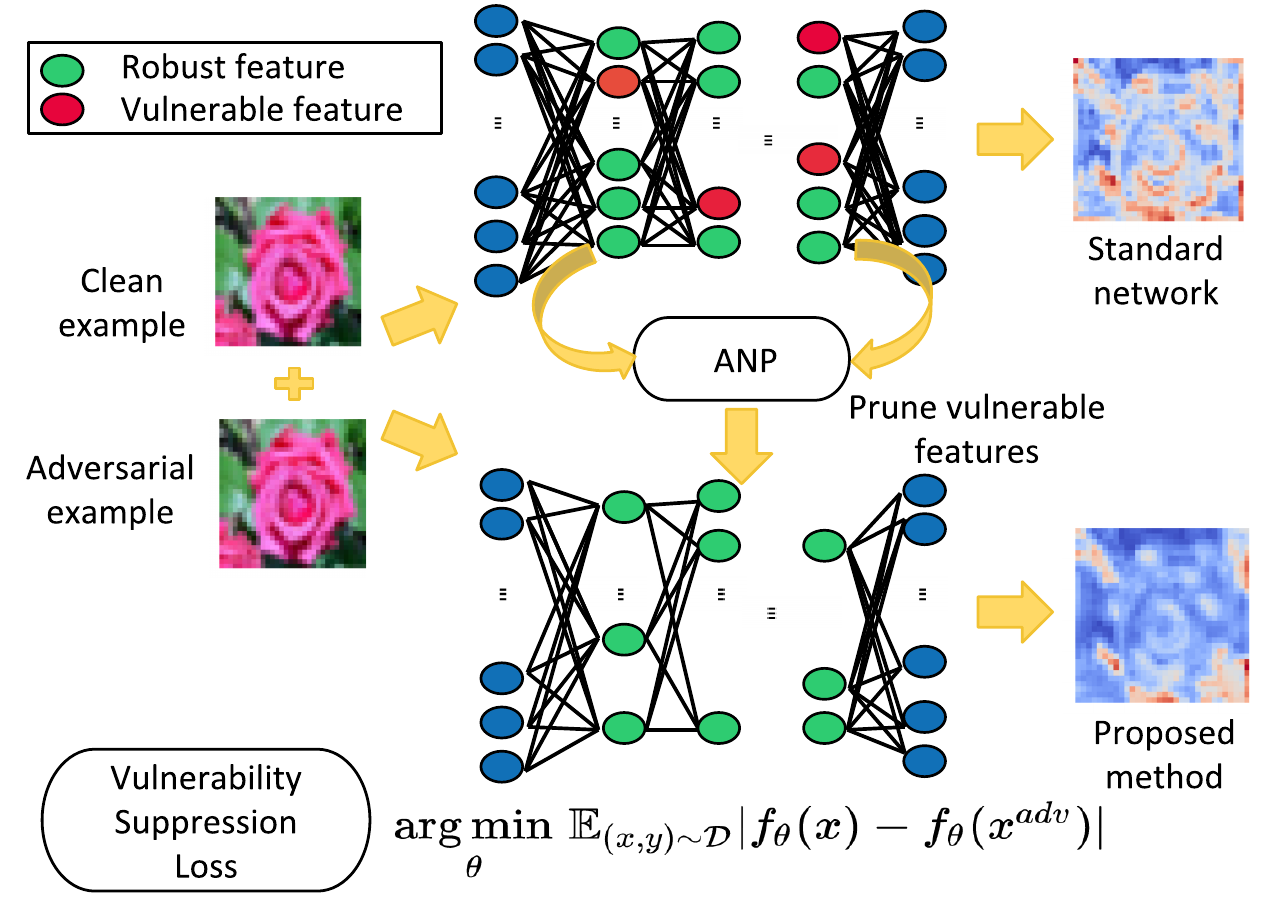
It effectively suppresses the distortion in the latent feature space with almost no extra cost relative to adversarial training and yields light-weighted networks that are more robust to adversarial perturbations.
Our Findings
We experimentally validate our proposed method on various datasets against various adversarial robustness and compression baselines. The table below contains the main results of our work.
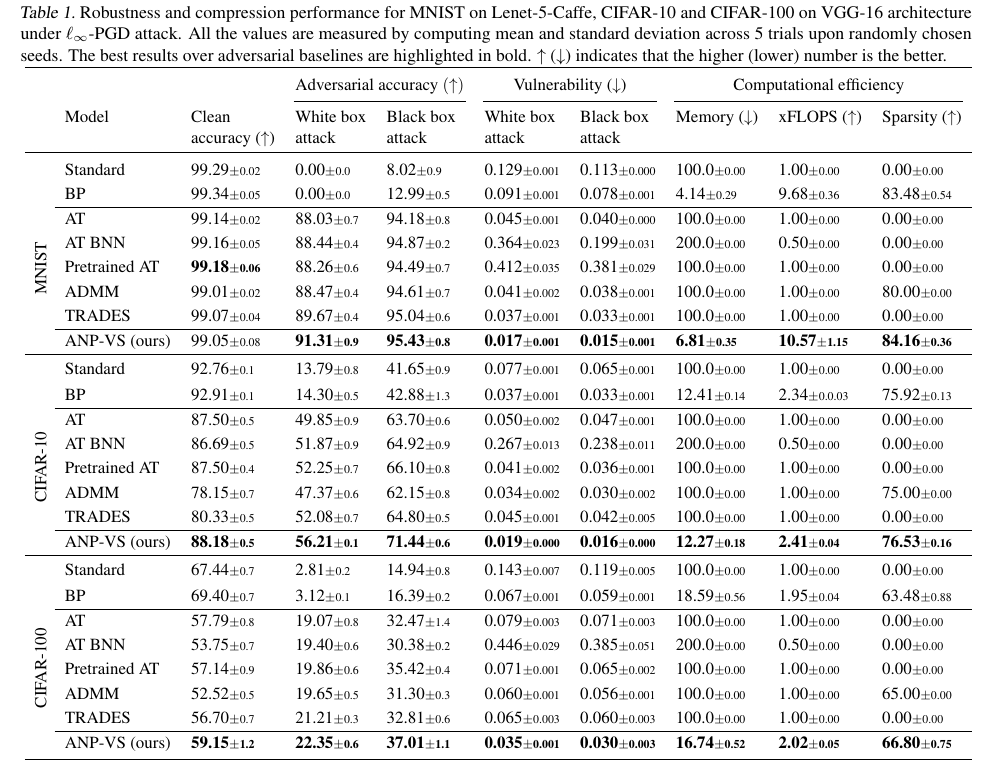
We can observe that ANP-VS consistently improves the adversarial robustness with a significant reduction in vulnerability across both white-box and black box attacks. Interestingly, it is not only effective on adversarial robustness but also outperforms all the compared adversarial baselines on the standard generalization performance, and strongly support our hypothesis of obtaining robust features. Furthermore, compared to the baselines our method shows a significant reduction in the memory-footprint with fewer FLOPS, demonstrating the effectiveness of our method.
To further gain insights into our method, we visualize the histogram of the vulnerability of latent-features for input-layer where we represent the number of zeros in orange color:

We consistently see that standard Bayesian pruning zeros out some of the distortionsin the latent-features, and AT reduces the distortion levelof all the latent-features. On the other hand, our proposed method does both, with the largest number of latent-features with zero distortion and low distortion level in general. In this vein, we can say that ANP-VS demonstrates the effectiveness of our method as a defense mechanism by obtaining robust features utilizing pruning and latent vulnerability suppression.
Conclusion
We hypothesized that the adversarial vulnerability of deep neural networks comes from the distortion in the latent feature space since if they are suppressed at any layers of the deep network, they will not affect the prediction. Based on this hypothesis, we formally defined the vulnerability of a latent feature and proposed Adversarial Neural Pruning(ANP) as a defense mechanism to achieve adversarial robustness as well as a means of achieving a memory- and computation-efficient deep neural networks. Specifically, we proposed a Bayesian formulation that trains a Bayesian pruning (dropout) mask for adversarial robustness of the network. Then we introduced Vulnerabiltiy Suppression (VS) loss, that minimizes network vulnerability. To this end, we proposed Adversarial Neural Pruning with Vulnerability Suppression (ANP-VS), which prunes the vulnerable features by learning pruning masks for them, to minimize the adversarial loss and feature-level vulnerability. We experimentally validate ANP-VS on three datasets against recent baselines, and the results show that it significantly improves the robustness of the deep network, achieving state-of-the-art results on all the datasets. Further qualitative analysis shows that our method obtains more interpretable latent features compared to standard counterparts, effectively suppresses feature-level distortions, and obtains smoother loss surface. We hope that our work leads to more follow-up works on adversarial learning that investigates the distortion in the latent feature space, which we believe is a more direct cause of adversarial vulnerability.