Multi-Modal Data Spectrum
Multi-Modal Datasets are Multi-Dimensional
1Courant, NYU 2CDS, NYU 3Grossman, NYU 4CIFAR LMB
TL;DR
- We show that no multi-modal dataset is truly multi-modal, each measures different dimensions of multimodal learning with varying strengths of intra- and inter-modality dependencies.
- We use a simple modality shuffling framework to understand these dependencies. We encourage any benchmark creator or model evaluator to adopt this framework.
- Scaling or architectural changes don't help. Larger and more capable models get better at exploiting intra-modality dependencies.
Overview
Proposing new multimodal benchmarks and evaluating models on more and more of these benchmarks has been a common practice. For a new benchmark or model, there exist more than 200 benchmarks to choose from. Every paper evaluates on a different subset of these benchmarks. Every new benchmark is proposed to fix some limitations of the previous benchmarks.
Despite this, there is a lack of clarity on whether these benchmarks measure what we anticipate. For instance, when a model achieves 85% on a VQA dataset, what are we truly measuring? What datasets do we need to evaluate to make this statement? Are the benchmarks designed to measure multimodal abilities?
Some benchmarks claim to require both modalities, but follow-up papers demonstrate that models can solve the task with a single modality for a large number of examples in the dataset. There has been a cat-and-mouse game of benchmark development and subsequent circumvention. To minimize this, we conduct a systematic study to understand the interplay between intra-modality dependencies (the contribution of an individual modality to a target task) and inter-modality dependencies (the relationships between modalities and the target task).
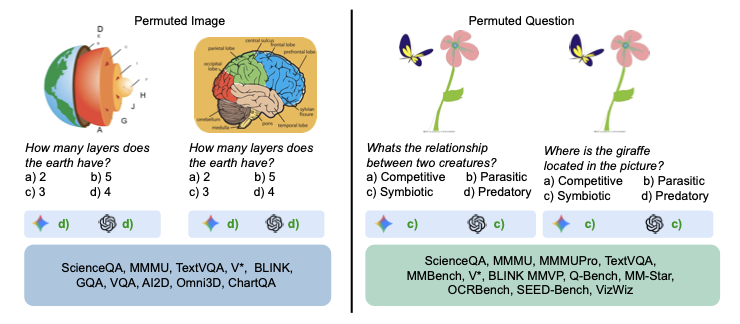
We evaluate on 23 multiple-choice visual question answering (MCVQA) benchmarks, spanning applications such as general visual question answering, knowledge-based reasoning, real-world spatial understanding, optical character recognition (OCR), and document and chart understanding. Across different model sizes and types, we find that MLLMs often exploit intra-modality dependencies, answering questions correctly even when a relevant input modality is replaced with corrupted or random data.
Quantifying the Multi-Modal Data Spectrum
For a multiple choice visual question answering task, given an image, a question, and a target answer selected from a set of options, the answer can be obtained with two types of dependencies:
Intra-modality dependency: The answer depends on a single modality. For instance, we can answer “How many layers does the Earth have?” using only the text.
Inter-modality dependency: The answer depends on the interaction between modalities. The image alone or the question independently cannot answer the question.
What Happens Right Now?
Most benchmarks have a mix of both, and we are often in the illusion of believing that the datasets primarily contain inter-modality dependencies. Out of the 23 datasets we evaluated, only four of them contained a domincance of inter-modality dependencies.
A new benchmark is often proposed to remove intra-modality dependencies in the previous benchmarks. Every time, models continue to use unanticipated intra-modality dependencies. Without a way to measure what dependencies a benchmark actually contains, we cannot make true progress.
What Can We Do Differently?
To measure this systematically, for each sample, we run the model under four conditions:
- Standard: Original image + original question
- Image only: Keep the image and options intact, replace the question with one from a random sample
- Text only: Keep the question and options intact, replace the image with one from a random sample
- Random: Replace both from random samples — this gives chance-level performance
We use modality shuffling instead of blank images or empty text because zeroing out inputs creates out-of-distribution artifacts that make models behave unpredictably. Shuffling captures the intra-modality dependencies between an individual modality and the label. To avoid being misled by quirks of any single model, we run this across multiple architectures and aggregate with a majority-vote ensemble.
Every Benchmark is Different
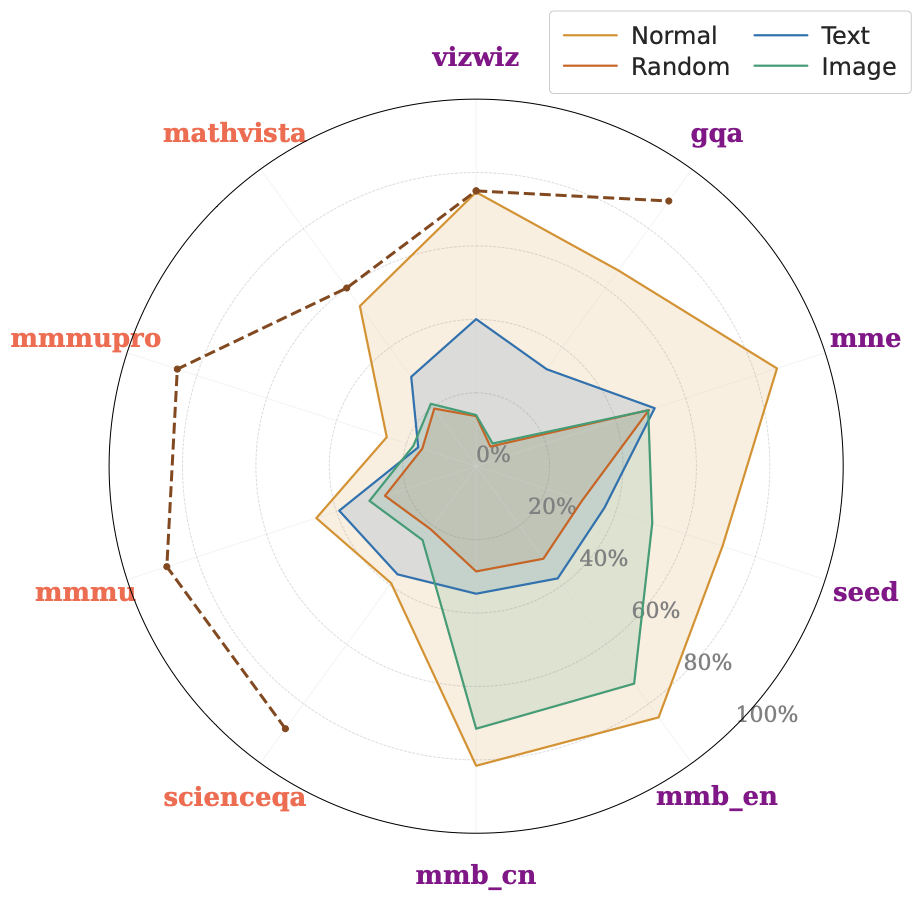
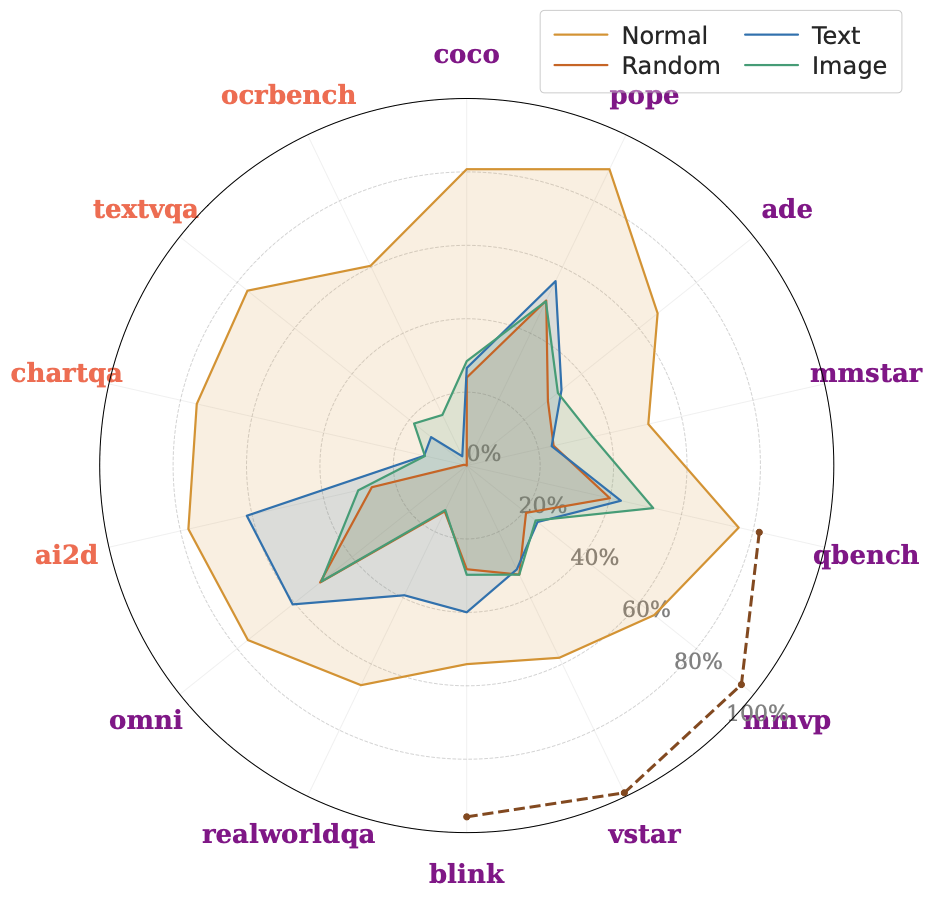
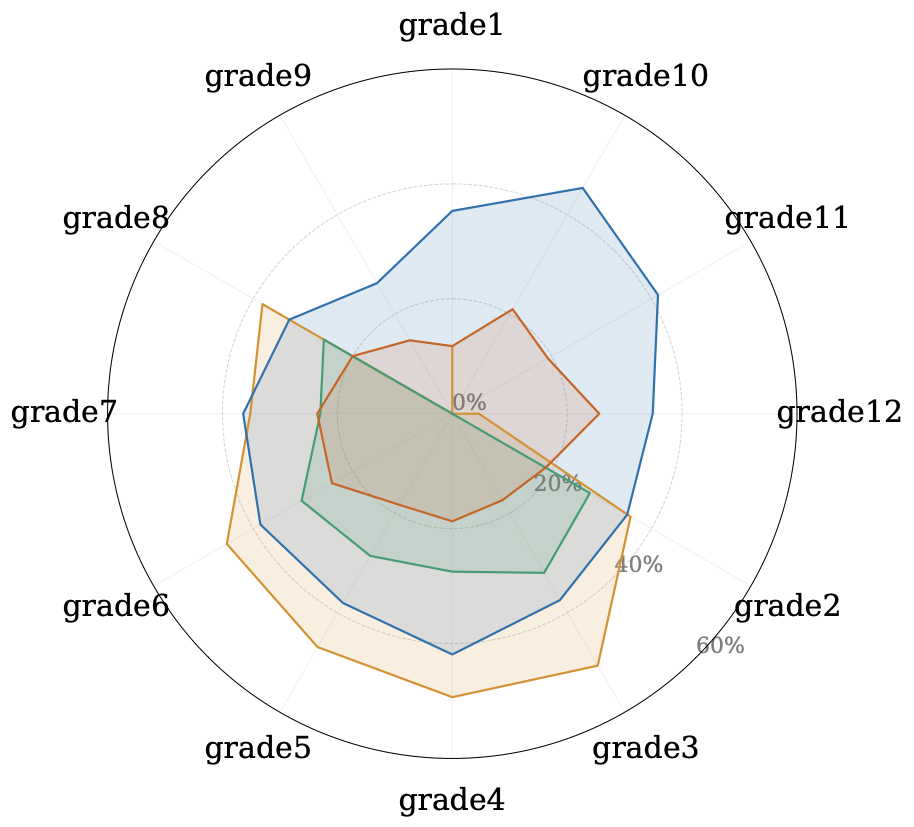
We ran this across 23 benchmarks spanning general VQA, knowledge-based reasoning, spatial understanding, OCR, chart comprehension. The radar plots show the ensemble performance under all four conditions. Some benchmarks are mostly solvable with just text, others with just the image, and some require both. Even within a benchmark, the model performance varies significantly.
We further show the performance for a few datasets across different model sizes and types. The dependencies remain mostly consistent across these varied model types and sizes.
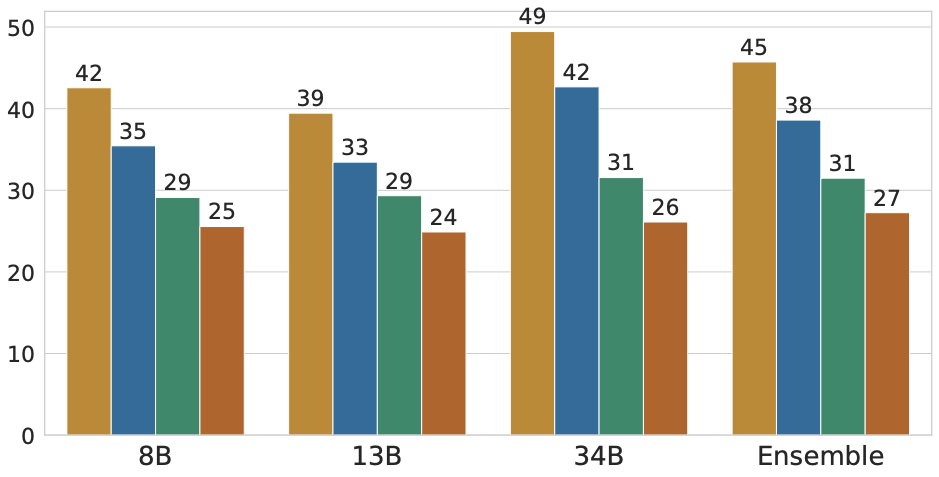
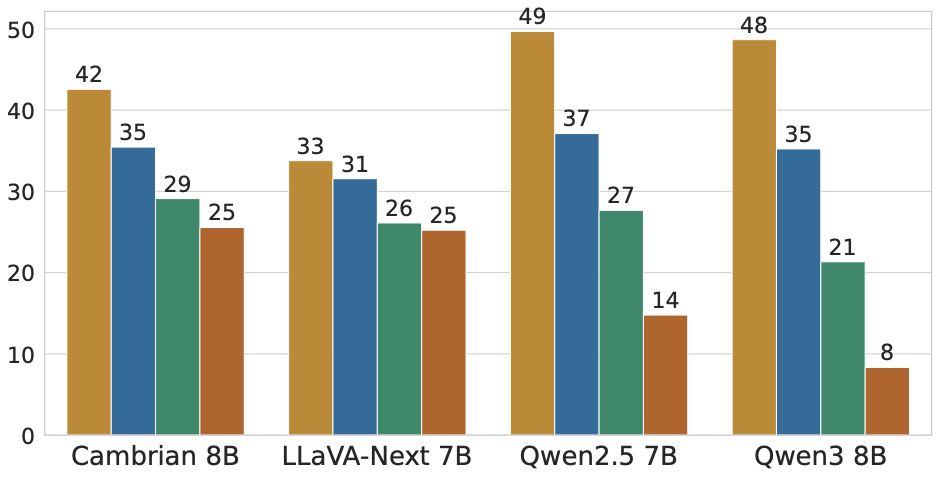
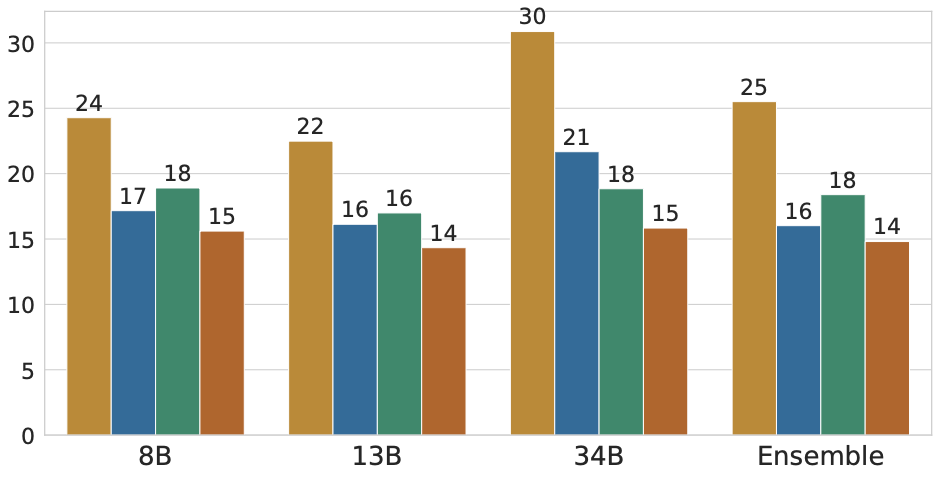
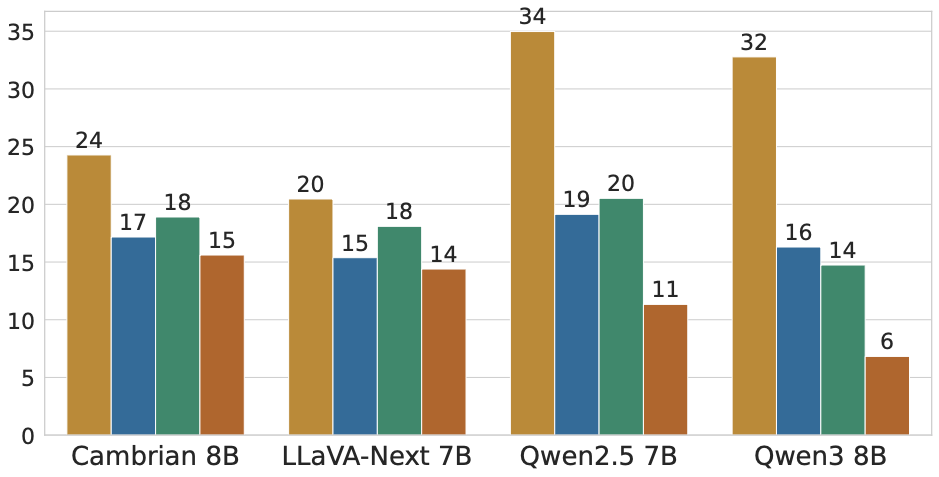
We also examine subcategory-level results, which reveal that even a benchmark that looks balanced overall can hide categories that are completely solvable from one modality.
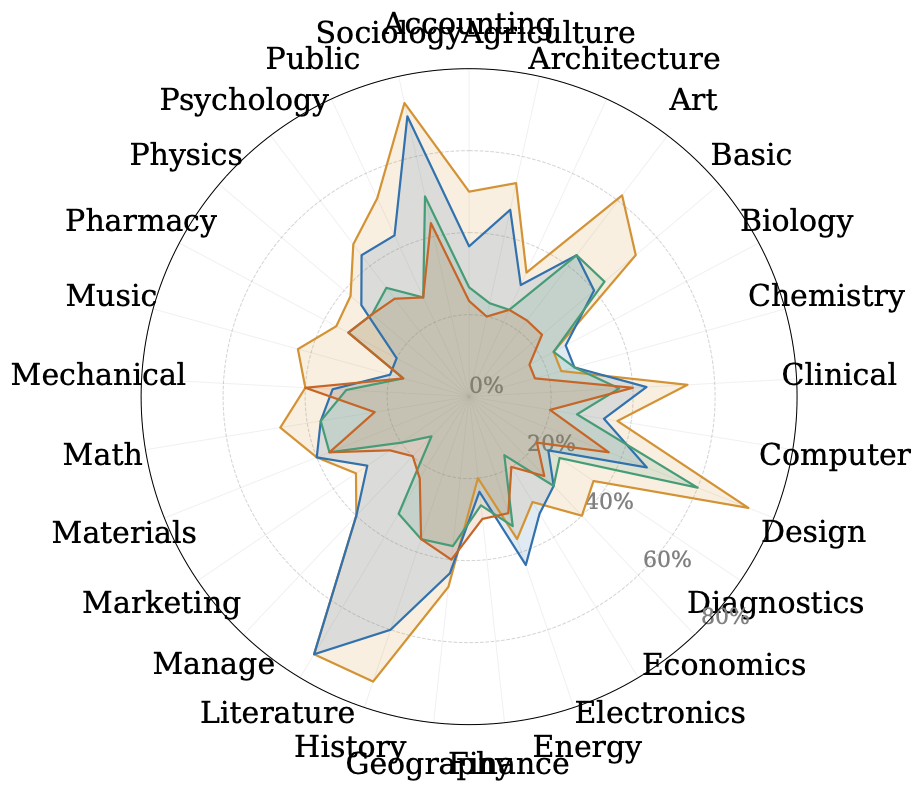
Recommendation
We wrote this paper because we think the field needs to measure what we are building through a benchmark and what we want to capture before building the next 200 benchmarks. A single accuracy number on a benchmark is not enough. We encourage future work to report what happens when you only use an individual modality for a given multimodal model. This is because even a benchmark that looks balanced overall can hide categories that are completely solvable from one modality.
We believe that meaningful progress in multimodal learning cannot be achieved simply by developing more benchmarks or chasing leaderboard metrics. Instead, we must critically assess the existing evaluation methods. This includes moving beyond standard multiple-choice formats, incorporating scenarios where models should abstain when they are uncertain, and examining how a model arrives at an answer rather than only what answer it produces.